Metoda výpočtu LANDUSE
Výchozí modelovací metodou je Markovův řetězec. Ze dvou vstupních map a z výstupu předchozího kroku model určí, k jaké očekávané přeměně dojde mezi pozdějším vstupním datem a uživatelem určeným datem budoucím (počet pixelů). Výstupem jsou dva soubory. První obsahuje matici pravděpodobnosti přechodu, pro každou kategorii, mezi časy t a t+1. Matice přechodu může být specifikována i pomocí jiného, externího modelu. Druhý výstup je matice obsahující pravděpodobný počet pixelů, určených ke změně. Při výpočtu jednotlivých pravděpodobností program postupuje následovně:
Nejprve určí tabulku vzájemných přeměn mezi historickými daty t1 a t2 (crosstabulation) a přepočte jednotlivé plochy na procenta. Tím vznikne základní matice přechodu, označme ji např. jako A. Nová matice přechodu, udávající přeměnu z novějšího roku do roku budoucího, je pak výsledek mocnění matice A, podle následujícího pravidla. Pokud je mezi historickými mapami krajinného pokryvu např. 5 let, pak matice přechodu pro rok t2+5 je A, pro rok t2 +10 A 2 , pro rok t2 +15 A 3 , atd. Pokud doba mezi projekčním rokem a historickým snímkem není násobkem doby mezi dvěma historickými snímky, jsou pomocí kvadratické interpolace určeny i mezilehlé hodnoty.
Základním krokem celého procesu je příprava vstupních dat, ze kterých následně probíhá predikce. Byly vytvořeny a použity tyto datové vrstvy: jako základní vstupní vrstvy slouží Corine Land Cover pro roky 1990, 2000, 2006, 2012; roli faktorů plní digitální model reliéfu (DMR), sklon reliéfu, vzdálenost od říční sítě, vzdálenost od zástavby, vzdálenost od silniční sítě a vrstva průměrné hustoty obyvatel ve sledovaném období.
Všechna data bylo nejprve nutno převést do rastrové podoby, a to konkrétně do formátu .rst, se kterým Land Change Modeler pracuje. Vzhledem k velikosti zájmového území (celá ČR) a definovanou šablonu byla zvolena podrobnost rastru 500 metrů / pixel. Bylo také nutno dodržet u všech rastrů jednotný souřadnicový systém, extent vrstvy, a hodnota pro NoData. Pro dodržení těchto podmínek bylo nejlepší originální soubory převádět přes formát ASCII a z něj následně do výsledného .rst. Tato sjednocené data mohly vstoupit do Land Change Modeleru.
Během modelování bylo nejprve vytvořeno několik dílčích predikcí roku 2050, a to z let 1990 – 2000, 2000 – 2006, 2006 – 2012 a 1990 – 2012. Tyto dílčí modely měly být následně spojeny dohromady pro finální predikci z let 1990 – 2012.
Predikce probíhá v následujících krocích: nejprve jsou nahrány vždy dvě vstupní vrstvy landcoveru, doplněny o vrstvu digitálního modelu reliéfu. Nad těmito vrstvami proběhne prvotní analýza změn, která nabízí přehled změn počtu pixelů v jednotlivých kategoriích. Změny jednotlivých kategorií je možno vizualizovat (obr. 1).
V následující kroku – stanovení Transition Potentials se analyzuje přehled jednotlivých přechodů – přechod jedné kategorie do jiné. Vzhledem k vysokému počtu vstupních kategorií (30) vzniklo velké množství těchto kombinací. Aby se snížila výpočetní náročnost modelu, byly ignorovány přechody mezi kategoriemi menší než 30 pixelů. Jednotlivé přechody lze seskupovat do submodelů a těm přiřazovat faktory.
Ke každému submodelu byly přiřazeny vrstvy faktoru – již výše zmíněný digitální model reliéfu, sklon reliéfu, vzdálenost od říční sítě, vzdálenost od zástavby, vzdálenost od silniční sítě a vrstva průměrné hustoty obyvatel ve sledovaném období. Faktory byly nastavené jako statické, protože sledovaným výsledkem je pevný časový bod. Takto připravené submodely byly postupně spouštěny. Modul sám určuje velikost testovací vzorku, ze kterého je počítána pravděpodobnost změny. Upraveny byly pouze extrémně nízké hodnoty (v řádech jednotek pixelů). K výpočtu je možno použít neuronových sítí, logistické regrese a nebo vážených faktorů. Zde bylo využito neuronových sítí.
Obr. 1 Ukázka změn počtu pixelů v Change Analysis
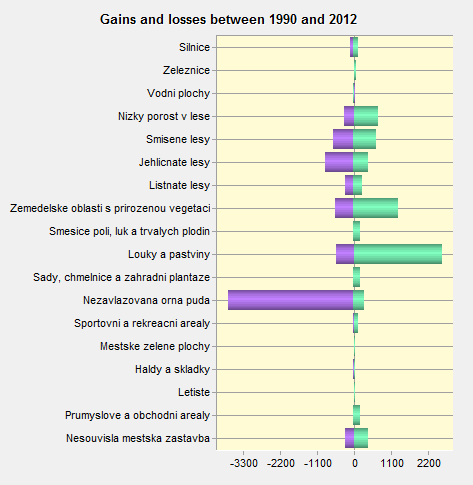
Pro proběhnutí všech submodelů vznikne tzv. matice pravděpodobnosti přechodu mezi kategoriemi. Tu je možno editovat, a je základem pro finální predikci. Postupně byly vytvořeny modely z let 1990, 2000, 2006 a 2012 a jejich matice přechodu byly zprůměrovány. Cílem této metody bylo nastavit pravděpodobnosti přechodu takové, aby co nejvíce vyhovovaly jednotlivým dílčím modelům. Zprůměrovaná matice byla nahrána do modelu, ke následně pomocí Markovových řetězců probíhá predikce. Posledním zásahem bylo vložení omezujících prvků, ve kterých nebude predikce počítána. Takovými plochami jsou v tomto případě chráněná území ČR.
Ústav výzkumu globální změny AV ČR v.v.i.
Bělidla 986/4a
603 00 Brno
+420 731 622 088, +420 545 133 094
info@czechglobe.cz